Recap of my first Kaggle Competition: Detecting Insults in Social Commentary [update 3]
Recently I entered my first kaggle competition - for those who don't know it, it is a site running machine learning competitions. A data set and time frame is provided and the best submission gets a money prize, often something between 5000$ and 50000$.
I found the approach quite interesting and could definitely use a new laptop, so I entered Detecting Insults in Social Commentary.
My weapon of choice was Python with scikit-learn - for those who haven't read my blog before: I am one of the core devs of the project and never shut up about it.
During the competition I was visiting Microsoft Reseach, so this is where most of my time and energy went, in particular in the end of the competition, as it was also the end of my internship. And there was also the scikit-learn release in between. Maybe I can spent a bit more time on the next competition.
The original data set was very small, ~3500 comments, each usually between 1 and 5 sentences.
One week before the deadline, another ~3500 data points where released (the story is a bit more complicated but doesn't matter so much). Some data points had timestamps (mostly missing in training but available in the second set and the final validation).
From some mail exchanges, comments in my blog and a thread I opened in the competition forum, I know that at least places 1, 2, 4, 5 and 6 (me) used scikit-learn for classification and / or feature extraction. This seems like a huge success for the project! I haven't heard from the third place, yet, btw.
Enough blabla, now to the interesting part:
First my code on github. Probably not so easy to run. Try my "working" branch of sklearn if you are interested.
The first uses character n-grams, some handcrafted features (in BadWordCounter), chi squared and logistic regression (output had to be probabilities):
The the second is very similar, but also used word-ngrams and actually preformed a little better on the final evaluation:
My final submission contained two more models and also the combination of all four. As expected, the combination performed better than any single model, but the improvement over char_model_word was not large (0.82590 AUC vs 0.82988 AUC, the winner had 0.84249).
Basically all parameters here are crazily cross-validated, but many are quite robust (C= 12 and percentile=4 will give about the same results).
Some of the magic happens obviously in BadWordCounter. You can see the implementation here, but I think the most significant features are "number of words in a badlist", "ratio of words that is in badlist", "ratio of words in ALL CAPS".
Here is a visualization of the largest coefficients of three of my model. Blue means positive sign (insult), red negative (not insult):
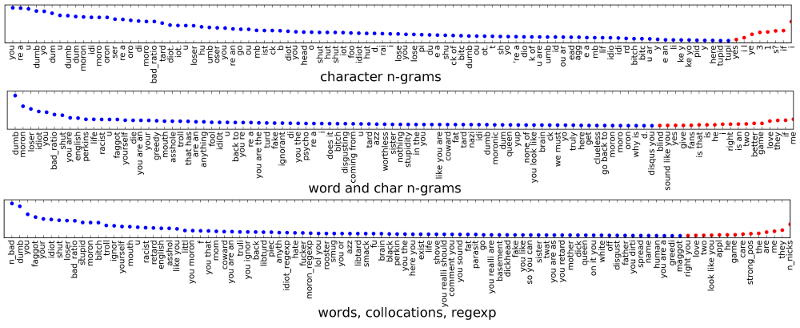
Most of the used features are quite intuitive, which I guess is a nice result (bad_ratio is the fraction of "bad" words, n_bad is the number).
But in particular the character plot looks pretty redundant, with most of the high positives detecting whether someone is a moron or idiot or maybe retarded...
Still it performs quite well (and of course these are only 100 of over 10,000 used features).
For the list of bad words, I used one that allegedly is also used by google.
As this will include "motherfucker" but not "idiot" or "moron" (two VERY important words in the training / leaderboard set), I extended the list with these and whatever the thesaurus said was "stupid".
Interestingly in some models, the word "fuck" had a very large negative weight.
I speculate this is caused by n_bad (the number of bad words) having a high weight and "fuck" not actually indicating insults.
As a side note: for the parameter selection, I used the ShuffleSplit (as Olivier suggested), as StratifiedKFold didn't seem to be very stable. I have no idea why.
I discovered very close to the end that there were some duplicates in the training set (I think one comment was present 5 times), which might have been messing with the cross-validation.
I also tried RFE, but didn't really get it to work. I am not so familiar with it and didn't know how to adjust the step-size to work in reasonable time with so many features.
I also gave the randomized logistic regression feature selection a shot (only briefly though), also without much success.
I also tried Bernoulli naive Bayes, KNN, and random forests (after L1 feature selection) to no avail.
What surprised me most was that I couldn't get SVC (LibSVM) to work.
The logistic regression I used (from LibLinear) was a lot better than the LibSVM with Platt-scaling. Therefore I didn't really try any fancy kernels.
I also tried to use the chi squared kernel approximation in RandomizedChi2,
as this often worked very well for bag of visual words, but didn't see any improvement.
I also played with jellyfish, which does some word stemming and standardization, but couldn't see an improvement.
A long complicated pipeline:
I also tried to put more effort into handcrafting the features and parsing the text.
I used sentence and word tokenizers from nltk, used collocations, extracted features using regex, even tried to count and correct spelling mistakes.
I briefly used part-of-speech tag histograms, but gave up on POS-tagging as it was very slow.
You can look up the details of what I tried here.
The model using these features was by far the worst. I didn't use any character features, but many many handcrafted ones. And it didn't really overfit.
It was also pretty bad on the cross-validation on which I designed the features.
Apparently I didn't really find the features I was missing.
I also used a database of positive and negative connotated words.
I should probably have tried to combine each of these features with the other classifiers, though I wanted to avoid building to similar models (as I wanted to average them). Also I didn't really invest enough time to do that (my internship was more important to me).
They basically focused on text feature extraction, parameter selection with grid search and feature selection.
These are:
Also, it seems to me that the simplest model worked best, feature selection and feature extraction are very important, though hand-crafting features is very non-trivial.
To recap: my best single model was the "char_word_model", which can be constructed in 7 lines of sklearn stuff, together with 30 lines for custom feature extraction. I think if I had added also the date, I might have had a good chance.
word and character n-grams and some form of counting swearwords.
Vivek, who won, found that SVMs worked better for him than logistic regression. Chris Brew, who came in fourth, only used character n-grams
and a customized SGD classifier. So even with very simple features, you can
get very far.
It seems most people didn't use feature selection, which I tried a lot.
The most commonly used software was scikit-learn, as I said above, R, and software from the Stanford NLP group.
For details on what others used, see the discussion in the kaggle forum.
After the first version of this blog-post (which I now shamelessly rewrote), I got a huge amount (relatively speaking) of feedback from other competitors.
Thanks to everybody who shared there methods - in the comments, at kaggle, and at the scikit-learn mailing list - and even their code!
I feel it is great that even though this is a competition and money is involved, we can openly discuss what we use and what works. I think this will help push the "data science" community and also will help us create better tools.
There where several thing that seemed a bit weird about the competition.
I know the competitions are generally still somewhat in a beta, phase, but there are some things that could be improved:
The scores from the leader board dropped significantly, from around 91 AUC to around 83 AUC on the final evaluation. I'm pretty sure I did not overfit (in particular the leader board score was always close to my cross validation score and I only scored on the leader board 4 times). Some discussion about this is here. Generally speaking, some sanity tests on the data sets would be great.
I was a bit disappointed during the competition as cross-validation seemed very noisy and my standard deviation captured the scores of the first 15 places.
That also made it hard to see which changes actually helped.
Also, there seemed to be a high amount of label noise.
For example most of my models had this false positive:
Are you retarded faggot lol If you are blind and dont use widgets then that doesnt mean everyone else does n't use them Widgets is one of the reasons people like android and prefer it agains iOS You can have any types of widgets for weather seeing your twitter and stuff and on ios you scroll like an idiot like a minute and when you finally found the apps you still have to click a couple of times before you see what you need Android 2:0 iOS ; ]
Hope you enjoyed this lengthy post :)
I found the approach quite interesting and could definitely use a new laptop, so I entered Detecting Insults in Social Commentary.
My weapon of choice was Python with scikit-learn - for those who haven't read my blog before: I am one of the core devs of the project and never shut up about it.
During the competition I was visiting Microsoft Reseach, so this is where most of my time and energy went, in particular in the end of the competition, as it was also the end of my internship. And there was also the scikit-learn release in between. Maybe I can spent a bit more time on the next competition.
The Task
The task was to classify forum posts / comments into "insult" and "not insult".The original data set was very small, ~3500 comments, each usually between 1 and 5 sentences.
One week before the deadline, another ~3500 data points where released (the story is a bit more complicated but doesn't matter so much). Some data points had timestamps (mostly missing in training but available in the second set and the final validation).
The Result (Spoiler alert)
I made 6th place. Vivek Sharma won.From some mail exchanges, comments in my blog and a thread I opened in the competition forum, I know that at least places 1, 2, 4, 5 and 6 (me) used scikit-learn for classification and / or feature extraction. This seems like a huge success for the project! I haven't heard from the third place, yet, btw.
Enough blabla, now to the interesting part:
First my code on github. Probably not so easy to run. Try my "working" branch of sklearn if you are interested.
Things That worked
My two best performing models are actually quite simple, so I'll just paste them here.The first uses character n-grams, some handcrafted features (in BadWordCounter), chi squared and logistic regression (output had to be probabilities):
select = SelectPercentile(score_func=chi2, percentile=18)
clf = LogisticRegression(tol=1e-8, penalty='l2', C=7)
countvect_char = TfidfVectorizer(ngram_range=(1, 5),
analyzer="char", binary=False)
badwords = BadWordCounter()
ft = FeatureStacker([("badwords", badwords), ("chars", countvect_char), ])
char_model = Pipeline([('vect', ft), ('select', select), ('logr', clf)])
The the second is very similar, but also used word-ngrams and actually preformed a little better on the final evaluation:
select = SelectPercentile(score_func=chi2, percentile=16)
clf = LogisticRegression(tol=1e-8, penalty='l2', C=4)
countvect_char = TfidfVectorizer(ngram_range=(1, 5),
analyzer="char", binary=False)
countvect_word = TfidfVectorizer(ngram_range=(1, 3),
analyzer="word", binary=False, min_df=3)
badwords = BadWordCounter()
ft = FeatureStacker([("badwords", badwords), ("chars", countvect_char),
("words", countvect_word)])
char_word_model = Pipeline([('vect', ft), ('select', select), ('logr', clf)])
My final submission contained two more models and also the combination of all four. As expected, the combination performed better than any single model, but the improvement over char_model_word was not large (0.82590 AUC vs 0.82988 AUC, the winner had 0.84249).
Basically all parameters here are crazily cross-validated, but many are quite robust (C= 12 and percentile=4 will give about the same results).
Some of the magic happens obviously in BadWordCounter. You can see the implementation here, but I think the most significant features are "number of words in a badlist", "ratio of words that is in badlist", "ratio of words in ALL CAPS".
Here is a visualization of the largest coefficients of three of my model. Blue means positive sign (insult), red negative (not insult):
Most of the used features are quite intuitive, which I guess is a nice result (bad_ratio is the fraction of "bad" words, n_bad is the number).
But in particular the character plot looks pretty redundant, with most of the high positives detecting whether someone is a moron or idiot or maybe retarded...
Still it performs quite well (and of course these are only 100 of over 10,000 used features).
For the list of bad words, I used one that allegedly is also used by google.
As this will include "motherfucker" but not "idiot" or "moron" (two VERY important words in the training / leaderboard set), I extended the list with these and whatever the thesaurus said was "stupid".
Interestingly in some models, the word "fuck" had a very large negative weight.
I speculate this is caused by n_bad (the number of bad words) having a high weight and "fuck" not actually indicating insults.
As a side note: for the parameter selection, I used the ShuffleSplit (as Olivier suggested), as StratifiedKFold didn't seem to be very stable. I have no idea why.
I discovered very close to the end that there were some duplicates in the training set (I think one comment was present 5 times), which might have been messing with the cross-validation.
Things that didn't work
Feature selection:
I tried L1 features selection with logistic regression followed by L2 penalized Logistic regression, though it was worse than univariate selection in all cases.I also tried RFE, but didn't really get it to work. I am not so familiar with it and didn't know how to adjust the step-size to work in reasonable time with so many features.
I also gave the randomized logistic regression feature selection a shot (only briefly though), also without much success.
Classifiers:
One of my submissions used elastic net penalized SGD, but that also turned out to be a bit worse than Logistic Regression.I also tried Bernoulli naive Bayes, KNN, and random forests (after L1 feature selection) to no avail.
What surprised me most was that I couldn't get SVC (LibSVM) to work.
The logistic regression I used (from LibLinear) was a lot better than the LibSVM with Platt-scaling. Therefore I didn't really try any fancy kernels.
Features:
I tried to use features from PCA and K-Means (distance to centers).I also tried to use the chi squared kernel approximation in RandomizedChi2,
as this often worked very well for bag of visual words, but didn't see any improvement.
I also played with jellyfish, which does some word stemming and standardization, but couldn't see an improvement.
A long complicated pipeline:
I also tried to put more effort into handcrafting the features and parsing the text.
I used sentence and word tokenizers from nltk, used collocations, extracted features using regex, even tried to count and correct spelling mistakes.
I briefly used part-of-speech tag histograms, but gave up on POS-tagging as it was very slow.
You can look up the details of what I tried here.
The model using these features was by far the worst. I didn't use any character features, but many many handcrafted ones. And it didn't really overfit.
It was also pretty bad on the cross-validation on which I designed the features.
Apparently I didn't really find the features I was missing.
I also used a database of positive and negative connotated words.
I should probably have tried to combine each of these features with the other classifiers, though I wanted to avoid building to similar models (as I wanted to average them). Also I didn't really invest enough time to do that (my internship was more important to me).
Things I implemented
I made several additions to scikit-learn particularly for this competition.They basically focused on text feature extraction, parameter selection with grid search and feature selection.
These are:
Merged
- Enable grid searches using Recursive Feature Elimination. (PR)
- Add minimum document frequency option to CountVectorizer (n-gram based text feature extraction) (PR)
- Sparse Matrix support in Recursive Feature Elimination. (PR)
- Sparse Matrix support in Univariate Feature Selection. (PR)
- Enhanced grid search for n-gram extraction. (PR)
- Add AUC scoring function. (PR)
- MinMaxScaler: Scale data feature-wise between given values (i.e. 0-1). (PR)
Not merged (yet)
- FeatureUnion: use several feature extraction methods and concatenate features. (PR)
- Sparse matrix support in randomized logistic regression (PR).
- Enhanced visualization and analysis of grid searches. (PR)
- Allow grid search using AUC scores. (PR)
Things I learned
I learned a lot about how to process text. I never worked with any text data before and I think now I have a pretty good grip on the general idea. The data was quite small for this kind of application but still I think I got a little feel.Also, it seems to me that the simplest model worked best, feature selection and feature extraction are very important, though hand-crafting features is very non-trivial.
To recap: my best single model was the "char_word_model", which can be constructed in 7 lines of sklearn stuff, together with 30 lines for custom feature extraction. I think if I had added also the date, I might have had a good chance.
Things that worked for others
Most contestants used similar models as I did, i.e. linear classifiers,word and character n-grams and some form of counting swearwords.
Vivek, who won, found that SVMs worked better for him than logistic regression. Chris Brew, who came in fourth, only used character n-grams
and a customized SGD classifier. So even with very simple features, you can
get very far.
It seems most people didn't use feature selection, which I tried a lot.
The most commonly used software was scikit-learn, as I said above, R, and software from the Stanford NLP group.
For details on what others used, see the discussion in the kaggle forum.
Final Comments
After the first version of this blog-post (which I now shamelessly rewrote), I got a huge amount (relatively speaking) of feedback from other competitors.
Thanks to everybody who shared there methods - in the comments, at kaggle, and at the scikit-learn mailing list - and even their code!
I feel it is great that even though this is a competition and money is involved, we can openly discuss what we use and what works. I think this will help push the "data science" community and also will help us create better tools.
There where several thing that seemed a bit weird about the competition.
I know the competitions are generally still somewhat in a beta, phase, but there are some things that could be improved:
The scores from the leader board dropped significantly, from around 91 AUC to around 83 AUC on the final evaluation. I'm pretty sure I did not overfit (in particular the leader board score was always close to my cross validation score and I only scored on the leader board 4 times). Some discussion about this is here. Generally speaking, some sanity tests on the data sets would be great.
I was a bit disappointed during the competition as cross-validation seemed very noisy and my standard deviation captured the scores of the first 15 places.
That also made it hard to see which changes actually helped.
Also, there seemed to be a high amount of label noise.
For example most of my models had this false positive:
Are you retarded faggot lol If you are blind and dont use widgets then that doesnt mean everyone else does n't use them Widgets is one of the reasons people like android and prefer it agains iOS You can have any types of widgets for weather seeing your twitter and stuff and on ios you scroll like an idiot like a minute and when you finally found the apps you still have to click a couple of times before you see what you need Android 2:0 iOS ; ]
Hope you enjoyed this lengthy post :)




My code is really simple, probably simpler than yours, and came fourth. I completely agree that the final test dataset was so small that there is likely an element of luck in who placed where between (at least) 3 and 10.
ReplyDeleteI pushed it to github at https://github.com/cbrew/Insults.
Comments are welcome. One generally useful thing is a version of SGD classifier that uses cross-validation and warm starts to select how many iterations.
Do I see this correctly? You didn't use any features except character n-grams? And still beat me... crazy ;)
DeleteThanks for sharing :) I just moved back to Germany today. Once I settle in I'll have a look!
ReplyDeleteHere is my approach (#2): https://github.com/tuzzeg/detect_insults
ReplyDeleteComments are welcome as well.
Hey Dmitry. Thanks for sharing. You really put a lot more effort into the explanation than I did ;)
ReplyDeleteCool!
Great post Andy, makes me want to join a kaggle competition :-)
ReplyDeleteThanks :) If half of the sklearn devs start, competition will be a lot harder ;)
DeleteHello Andreas,
ReplyDeleteI wanted some help regarding compiler for scipy. When I run tests for successful installation of scikit, it gives error:
test_existing_double (test_scxx_object.TestObjectSetAttr) ... Could not locate executable g++
Executable g++ does not exist
ERROR
I would be grateful if you could help me with compiler settings.
Btw your approach to the problems seems interesting. :)
I am joining another kaggle competition about text classification, your solution is quite conducive to get me started! Thanks for your sharing:)
ReplyDelete